背景
通常我们会选择连续若干个epoch后train loss不下降时就降低lr(为方便讨论,这里统一选择减半lr)的策略。具体来说,train的时候通过计算eval分数判断best weight,同时记录last weight。但是在发现train loss无法下降时其实已经不是最好的时机,通过实验发现应该倒退回上一个best checkpoint的位置降低lr继续训练才对。具体现象和分析如下。
策略1
我们在step42180时发现无法继续降低loss,立即降低lr。降低lr后,train loss确实进一步下降了。
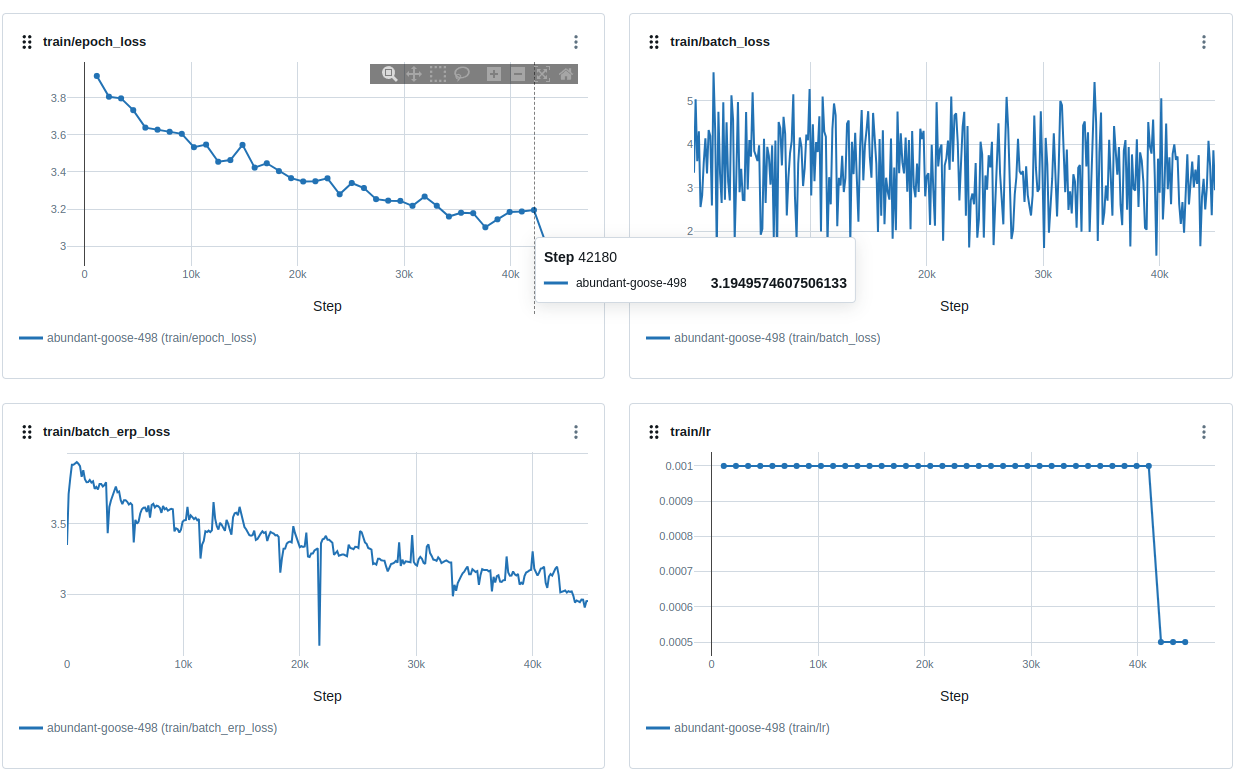
但是我们观察eval分数(eval图表显示的step实际上就是epoch),降低lr后,并没有继续下降,反而继续陡升。

这是因为我们在不合适的位置减少了搜索步长,在非至今位置找到的最佳位置进一步寻找局部最佳参数,这是不合理的。
策略2
我们退回eval取的最好分数的epoch34权重参数,手动降低lr。首先观察到,train loss是进一步下降的。
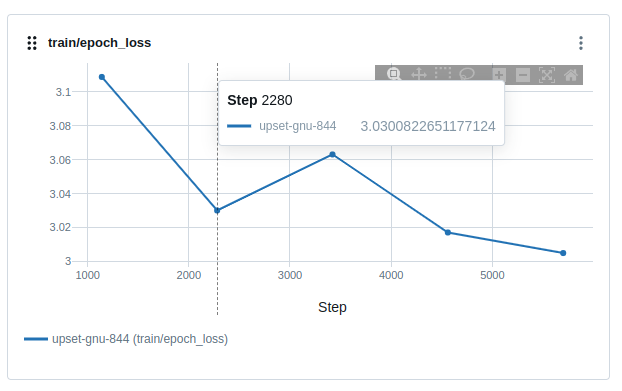
其次我们观察eval表现,也是效果继续提升,虽然也有波动,但是并没有陡升(精度退化)到很早以前分数的情况:

总结
比起就地减少lr,更好的策略是持续记录best weight,并在train loss无法继续降低,需要减少lr时,先退回best weight,再继续操作,记住:continue to train from best checkpoint rather than last one。