背景知识
Isotropic Gaussian
普通的一维高斯分布是“一座纸上画的山,一维,中心峰的x坐标由μ给出,表示分布的均值,μ∈R;山峰的宽度受方差σ2控制,σ∈(0,∞)”
而多维的高斯分布是“N维空间中的山,多维,中心峰的仍然是μ,仍表示分布的均值,不过μ为N维向量;山峰的宽度受协方差∑控制,∑是分布的协方差矩阵(性质:正定(特征值全是正数)对称的)。”
我们常常把协方差矩阵∑固定成一个对角阵(除了对角线其余位置的值都是0),而当我们使用协方差矩阵用一个标量乘以单位阵表示时,此时方差在各个方向都一样,就变成了一个更简单的版本——各向同性(isotropic)高斯分布。即就是方差在各个方向都一样。
各向同性的协方差矩阵是对角矩阵,而且对角线元素都相同。(各向同性指协方差矩阵为单位阵乘以正的常数)。即分布密度值仅跟点到均值距离相关,而不和方向有关。
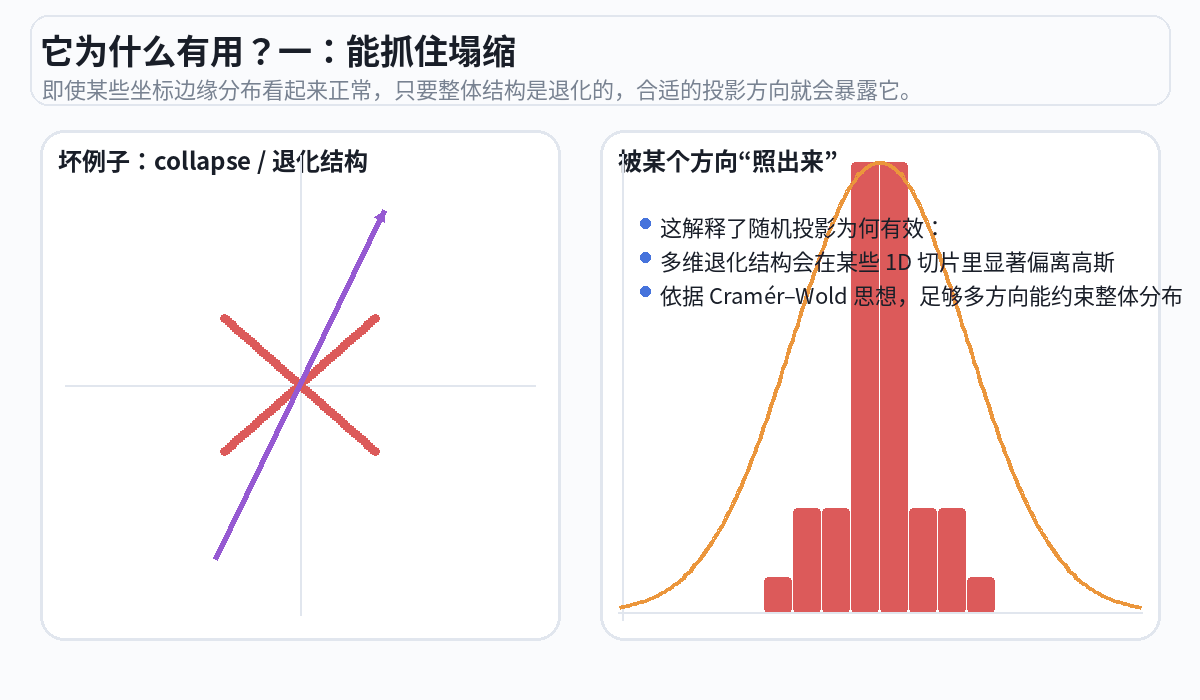
直观来看,各向同性(非对角位置值为0)的各个方向的分布不相关,如左图的3个例子:
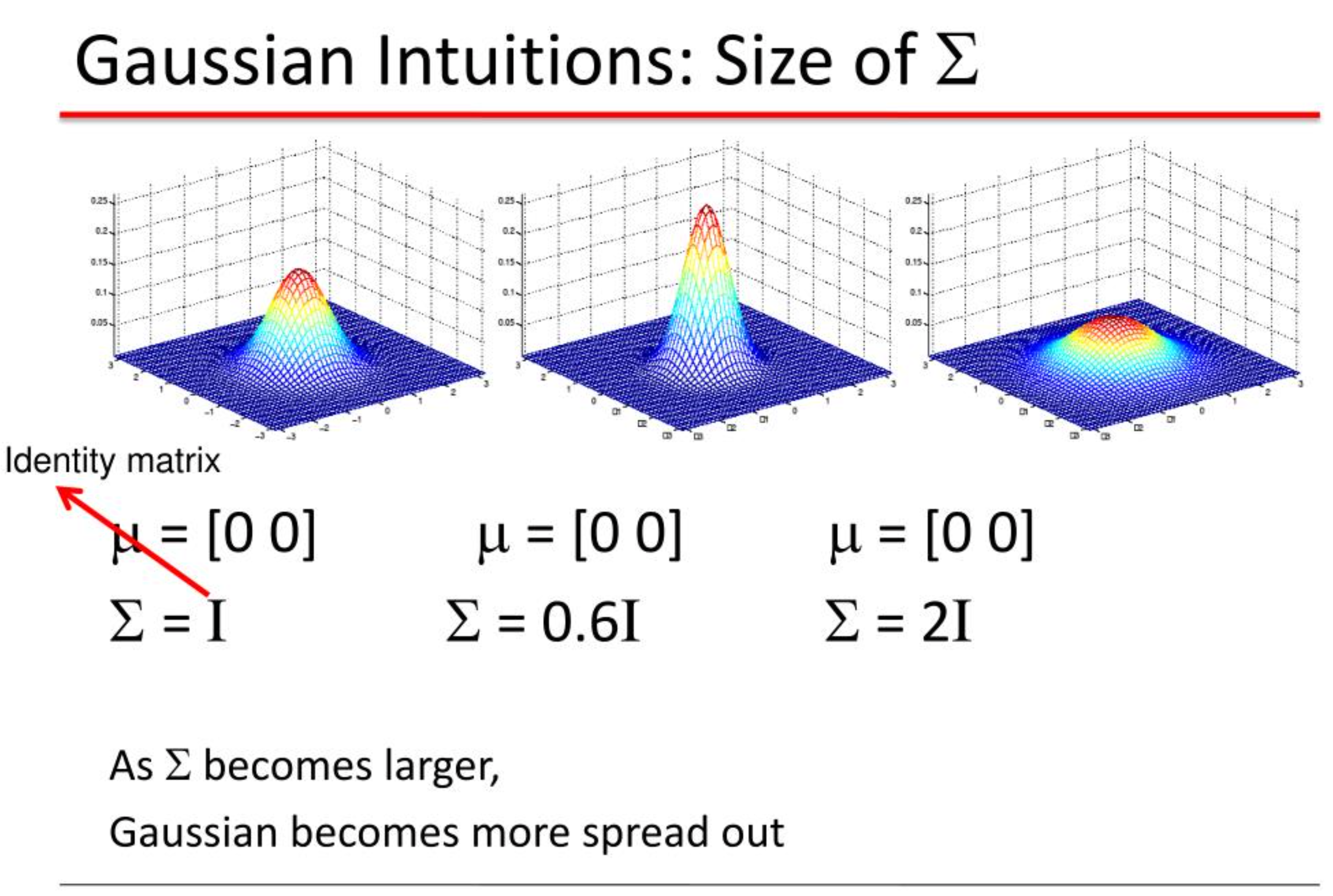
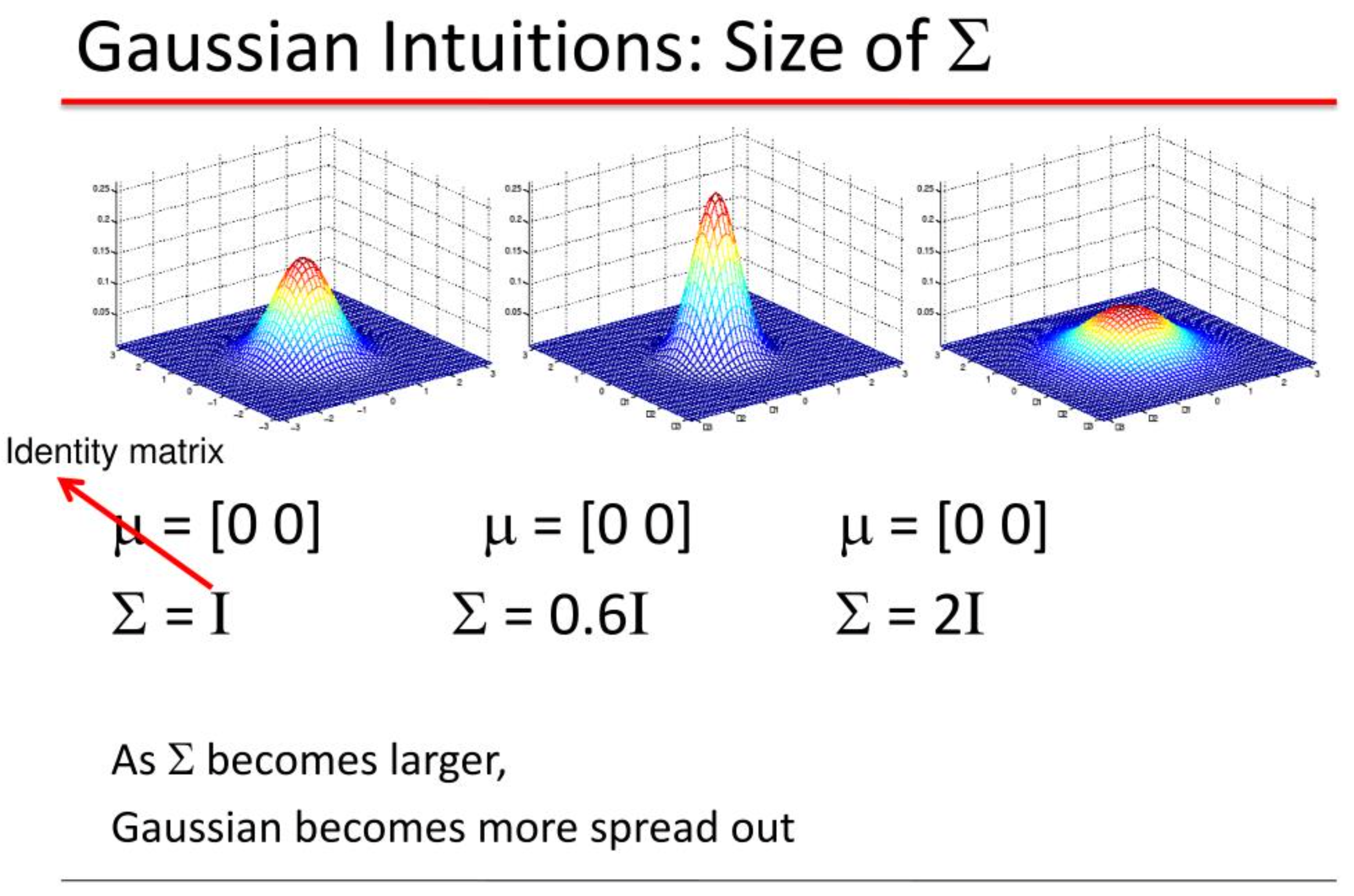
就是方差各个方向一样,协方差为正实数与identity matrix相乘。
因为高斯的circular symmetry,只需要让每个轴上的长度一样就能得到各向同性,也就是说分布密度值仅跟点到均值距离相关,而不和方向有关。
各向同性的高斯也是每个维度之间互相独立的,因此密度方程可以写成几个1维度高斯乘积形式。要注意的是,几个高斯分布乘在一起得到各向同性,但几个Laplace分布相乘就得不到各向同性。
有意思的点
关于世界模型的评价

思考:如果模型学会了贪吃蛇的游戏规则,那其实完全可以在不依赖数据的情况下,自己通过反复练习学会玩这个游戏。这个思路引申出另一个工作——Scaling Latent Reasoning via Looped Language Models,循环语言模型:同一层”多转几圈”,小模型碾压大模型。在token空间recurrently thinking这件事,有没有可能演进成,引导模型学习出自主对问题建模的能力,然后在自己建立的游戏框架下展开思考?
提出方法
如果单看LeWorldModel这一文,方法本身是很简单的。但是里面引用了 A Path Towards Autonomous Machine Intelligence 和 LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics的诸多结论,后面会补齐后面两文的学习文档。
言归正传,LeWorldModel主要说的就是3件事:
在embedding(latent)空间,考虑上一个latent与action,预测下一个latent,然后实施action,与新观测得到的latent对比,计算MSE,优化encoder。这与当下主流WM的做法是一样的;
predictor这边,会在latent空间根据trajactory(一系列action)演算每一步的z,直至末端,得到\hat{z}_H。然后与末端观测的embedding(latent)计算MSE。这里末端观测可以理解为y,与以往基于生成模型的x -> y求一个最佳预测器的优化范式不同,这里同时把x和y放到latent空间联合优化了,所以称之为Joint Embedding Predictive Architectures (JEPAs)。
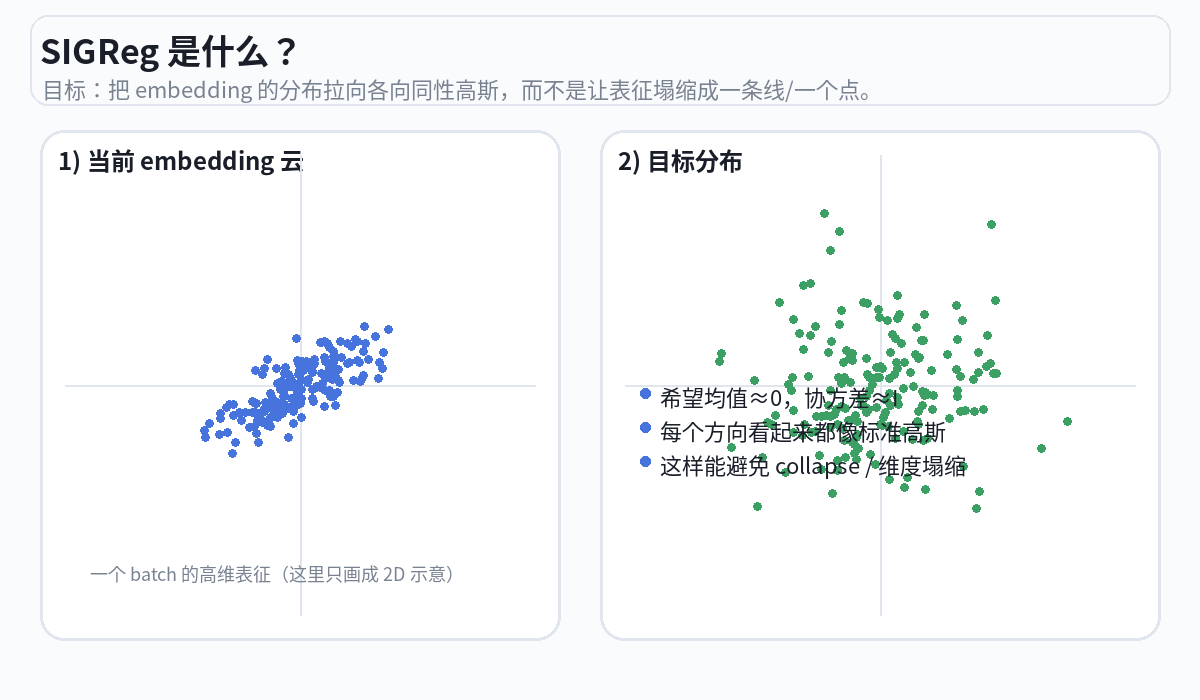
(本文核心贡献)综上的JEPA一直存在着representation collapse问题,大白话就是无论什么输入,都会被embedding到一个极小范围内的latent,导致完全失去表征能力。为此引入了名为SIGReg的正则化技巧,其核心思想是:强制 latent embeddings 的分布逼近标准各向同性高斯分布 N(0, I)。
补充:
为什么基于生成模型的 x -> y 不好?因为这逼着模型去处理所有细碎的噪声。而JEPA范式下模型可以自主决定“丢弃哪些信息”。如果某些细节无法被预测或者不值得预测(比如随机噪声),模型就会学着不去编码这些细节。
表示坍缩(representation collapse)的原因:预测器的目标是最小化预测误差 {\|\hat{z}_{t+1}-\hat{z}_{1}\|}^2,而编码器同时参与了生成预测的输入z_{t}和预测的目标z_{t+1}。编码器会发现一个"完美的偷懒方案":把所有输入都映射到同一个常数向量,这样预测误差恒为零。
为什么SIGReg有效?因为它解决了表征中的两种坍缩——如果 embedding 的分布是 N(0, I),意味着:每个维度的方差都是1(不会有维度"死掉"→ 防止维度坍缩);不同维度之间不相关(没有冗余 → 防止信息冗余坍缩)。
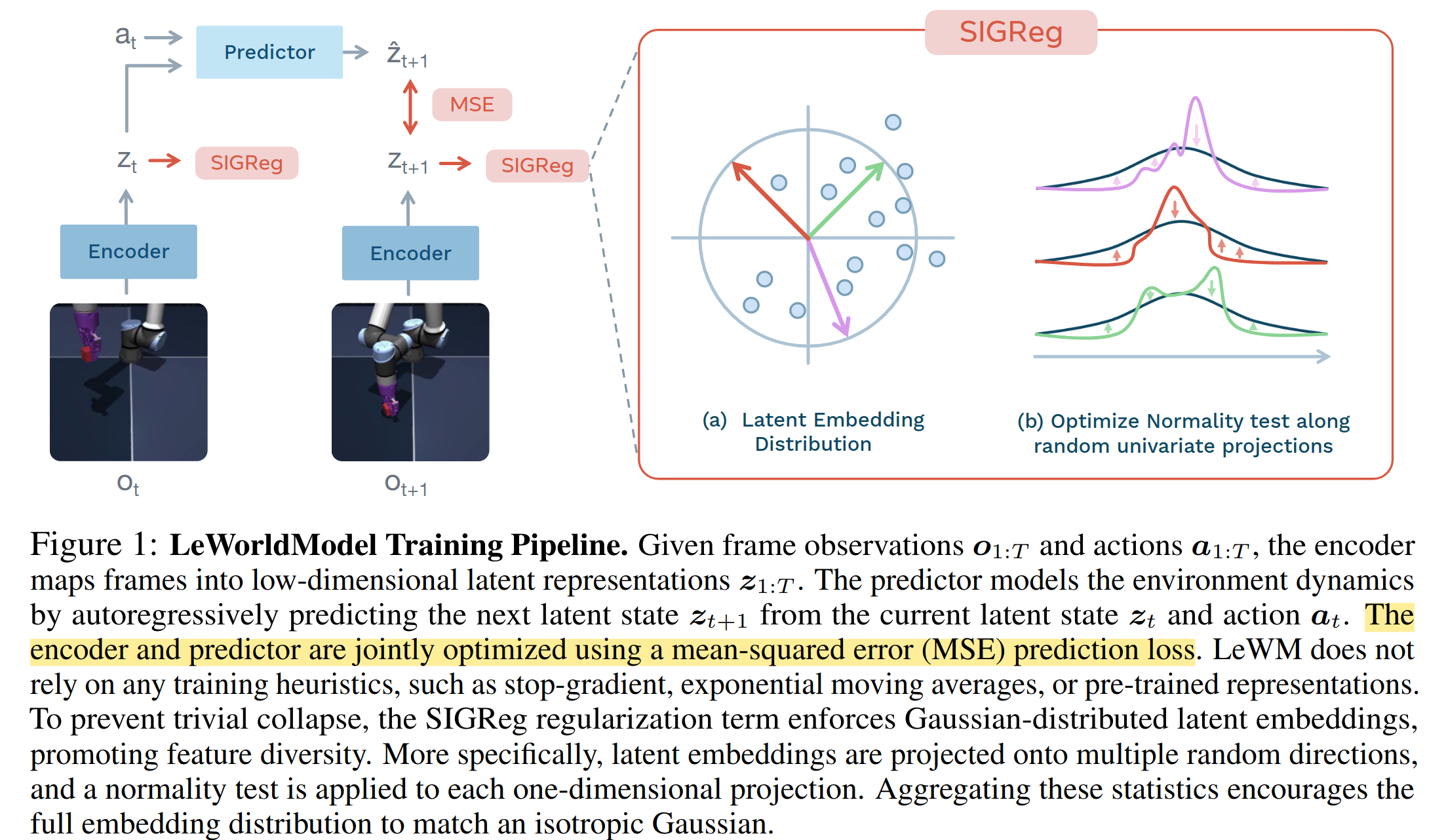

SIGReg
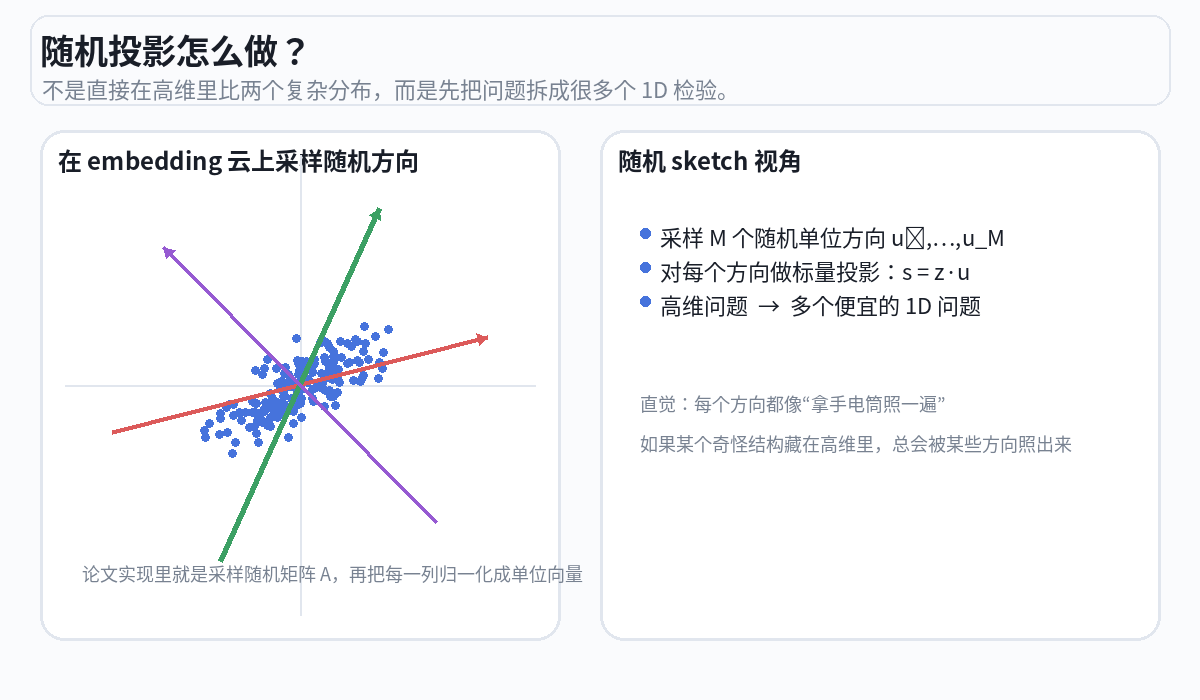
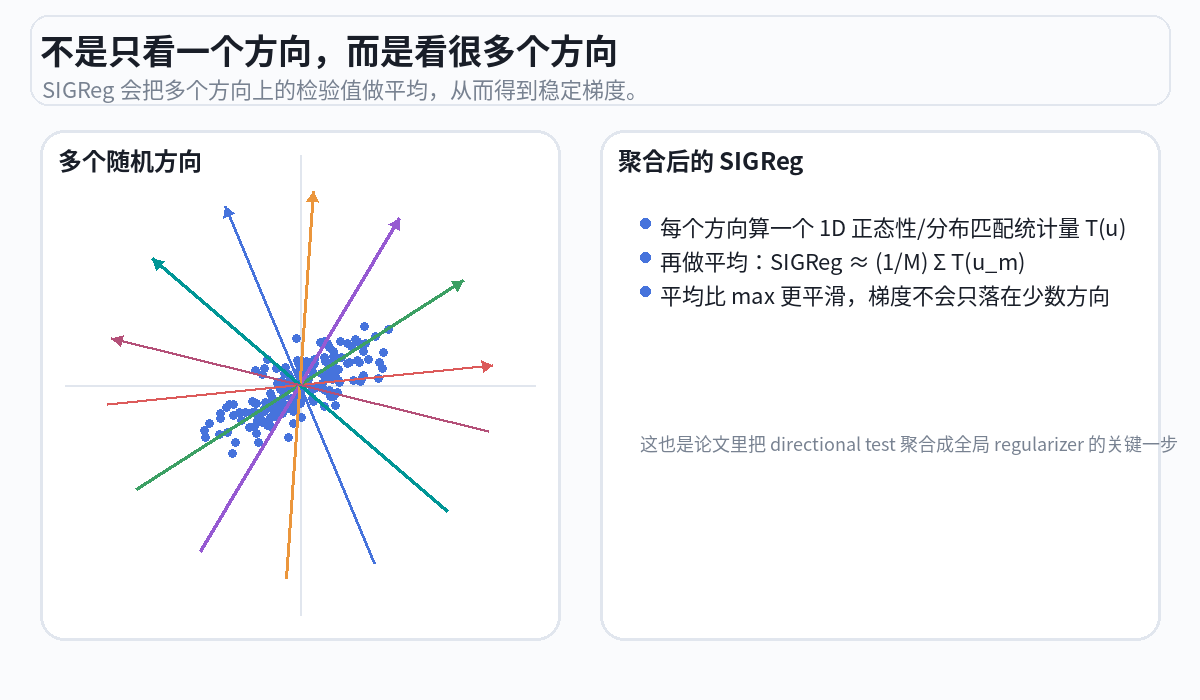
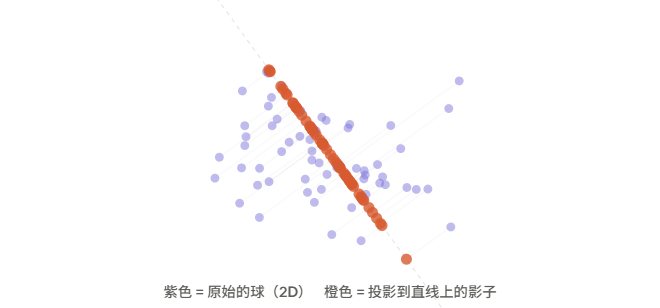
随机投影
随机选 1024 个方向,把所有球的"影子"投到每个方向上。就像用手电筒从不同角度照过去,看影子的分布。
这个方法之所以在数学上成立,是因为 Cramér-Wold 定理:如果从每一个方向看投影都是标准正态分布,那么原始的高维分布就一定是各向同性高斯。
# 1. 采样1024个随机单位方向
A = torch.randn(D, 1024)
A = A.div_(A.norm(p=2, dim=0))
# 2. 所有embedding投影到这些方向上
x_t = (proj @ A).unsqueeze(-1) * self.t # 投影 × 频率网格
# 3. 比较经验特征函数和标准正态的特征函数
err = (x_t.cos().mean(-3) - self.phi).square() + x_t.sin().mean(-3).square()
statistic = (err @ self.weights) * proj.size(-2)其中 self.t 不是一个标量,而是一个长度为K的频率点数组(频率网格)\left\{t_{1}, t_{2}, \ldots, t_{K}\right\}
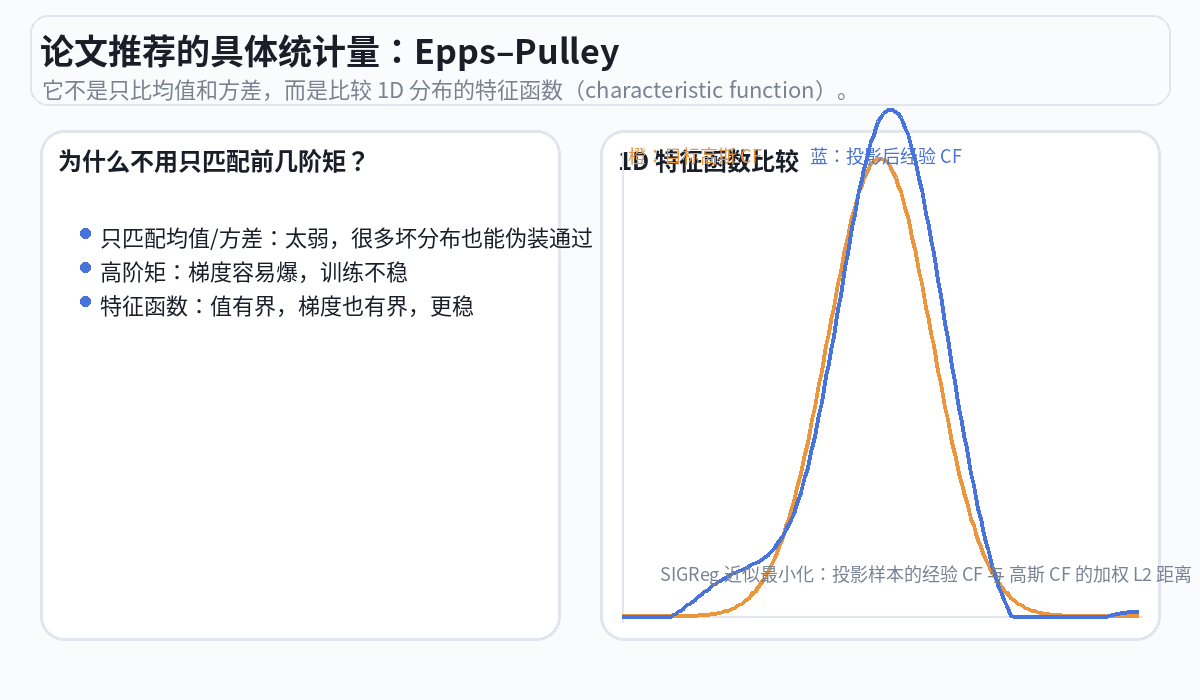
x_t.cos().mean() 是经验特征函数的实部,self.phi 是标准正态的特征函数(一个高斯形状的衰减函数),两者差距的加权平方和就是 Epps-Pulley 统计量。
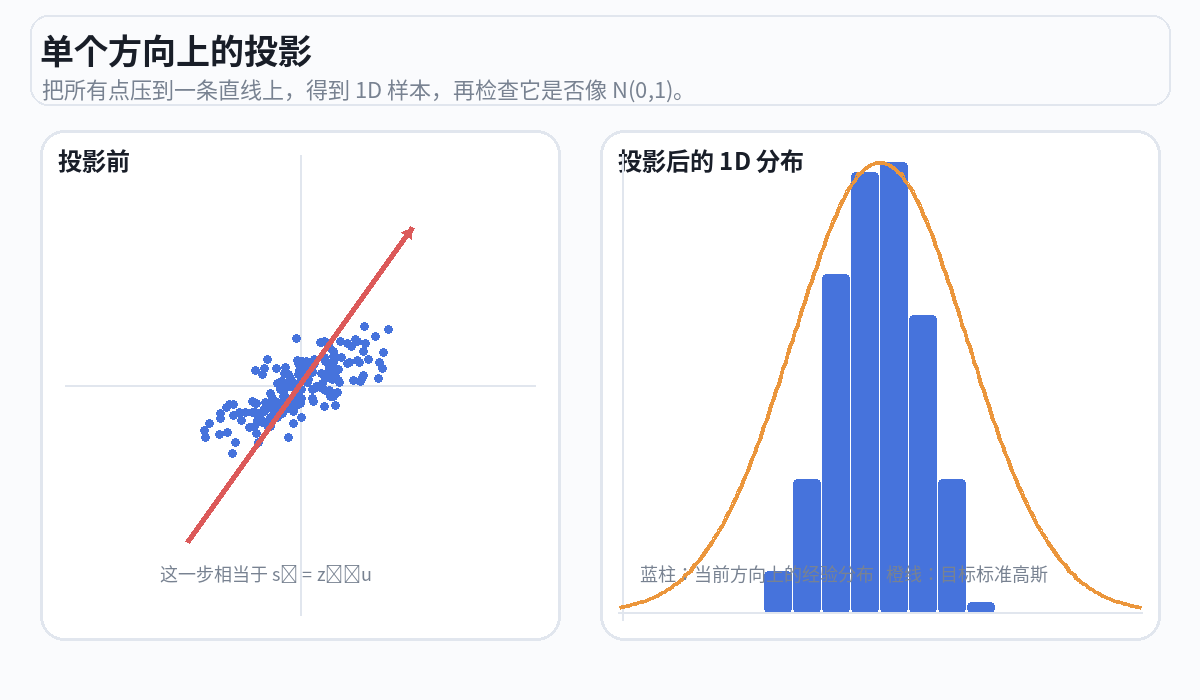
打分
对每个投影方向,SIGReg 用 Epps-Pulley 检验来评估"这个一维投影的分布有多接近标准正态"。如果接近,得分低(好);如果影子挤成一堆,得分高(差,需要惩罚编码器)。
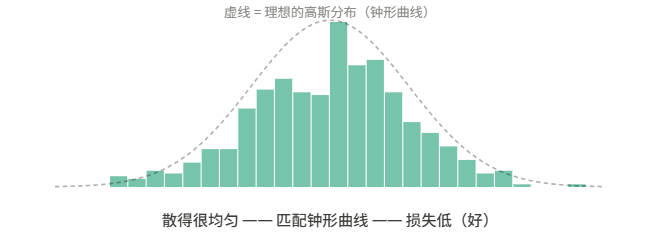
好的状态:投影后的分布 ≈ 钟形曲线 → SIGReg loss 低 → 编码器没有偷懒 坏的状态:投影后的分布 = 一个尖峰 → SIGReg loss 高 → 编码器在偷懒,需要惩罚。
涉及方法
除了论文本身提出的,还有一些使用到的方法。
Cross-Entropy Method
首先假定一个完美高斯分布
从里面采样,然后对样本打分,取topK作为elite samples
对 elite 做一次极大似然 / 拟合分布,论文这里是计算elite的均值与方差,然后回到上一步继续,或者满足条件后推出迭代
交叉熵方法(Cross-Entropy Method, CEM)没有显示的计算cross-entropy,在CEM中,“EM”的体现主要在于其算法逻辑与EM算法(期望最大化算法)在结构上的高度相似性。
CEM 本质上可以看作是一种用于稀疏事件概率估计或优化的特殊迭代过程,它的每一步都对应着 EM 的核心逻辑:
1. E-步(Expectation):采样与评估
在 EM 算法中,E-步是根据当前参数计算隐含变量的期望。
在 CEM 中,这对应于“采样”阶段:
动作:根据当前的概率分布(参数为
)随机生成一批样本。
体现:通过这些样本计算目标函数值,并筛选出“精英样本”(Elite Samples)。这些精英样本实际上是在当前分布下,对目标区域(或最优解所在区域)的一种经验期望估计。
2. M-步(Maximization):更新参数
在 EM 算法中,M-步是寻找使似然函数最大化的参数。
在 CEM 中,这对应于“拟合”阶段:
动作:利用筛选出的精英样本,通过最大似然估计(MLE)来更新分布参数,得到
。
体现:新的参数使得产生这些“精英样本”的概率最大化。也就是说,你通过最小化交叉熵,强制让下一代的分布向上一代的优秀样本靠拢。
3. 核心联系:KL散度的最小化
EM 算法的本质是不断缩小当前模型与真实分布之间的 KL 散度。
CEM 的名称来源正是因为它在每一步迭代中,都在尝试最小化“理想重要性采样分布”与“当前参数化分布”之间的交叉熵。这在数学形式上与 EM 算法通过迭代逼近最优分布的逻辑是完全一致的。
总结对比:
优点
单一超参数
工作的一个亮点是只有一个超参数需要调——控制MSE loss与SIGReg loss的权重 \lambda。作者也说了可以通过网格搜索(grid search)或者二分法(bisection strategy)很快的定位到最佳参数。
不挑结构

作者把tiny ViT换成了ResNet-18,网络精度并没有大幅下降,很大程度说明了方法对不同的网络结构都有很好的适用性。
实验
实验部分也很有意思
Probing physical quantities
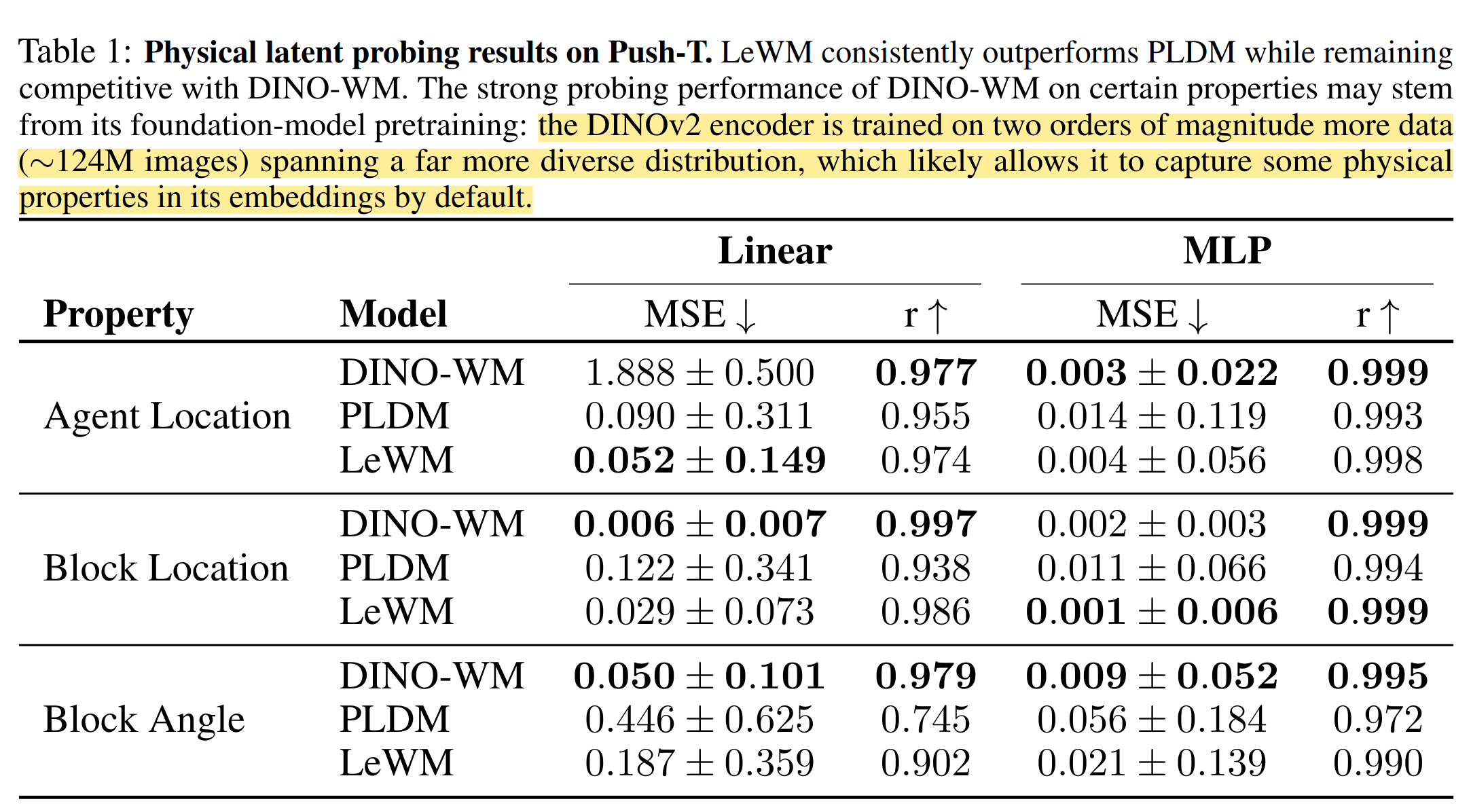
物理定量探针测试,WN常见的测试,让模型推理出环境的空间度量信息,比如这里就是测量突击之间的位置、角度。我觉得Linear更有说服力。我认为这个结果表明DINO预训练真的是为模型注入很强的环境表征能力,不知道LeWM如果scale up到一样测参数量之后会不会更强?
Decoding Latent Space
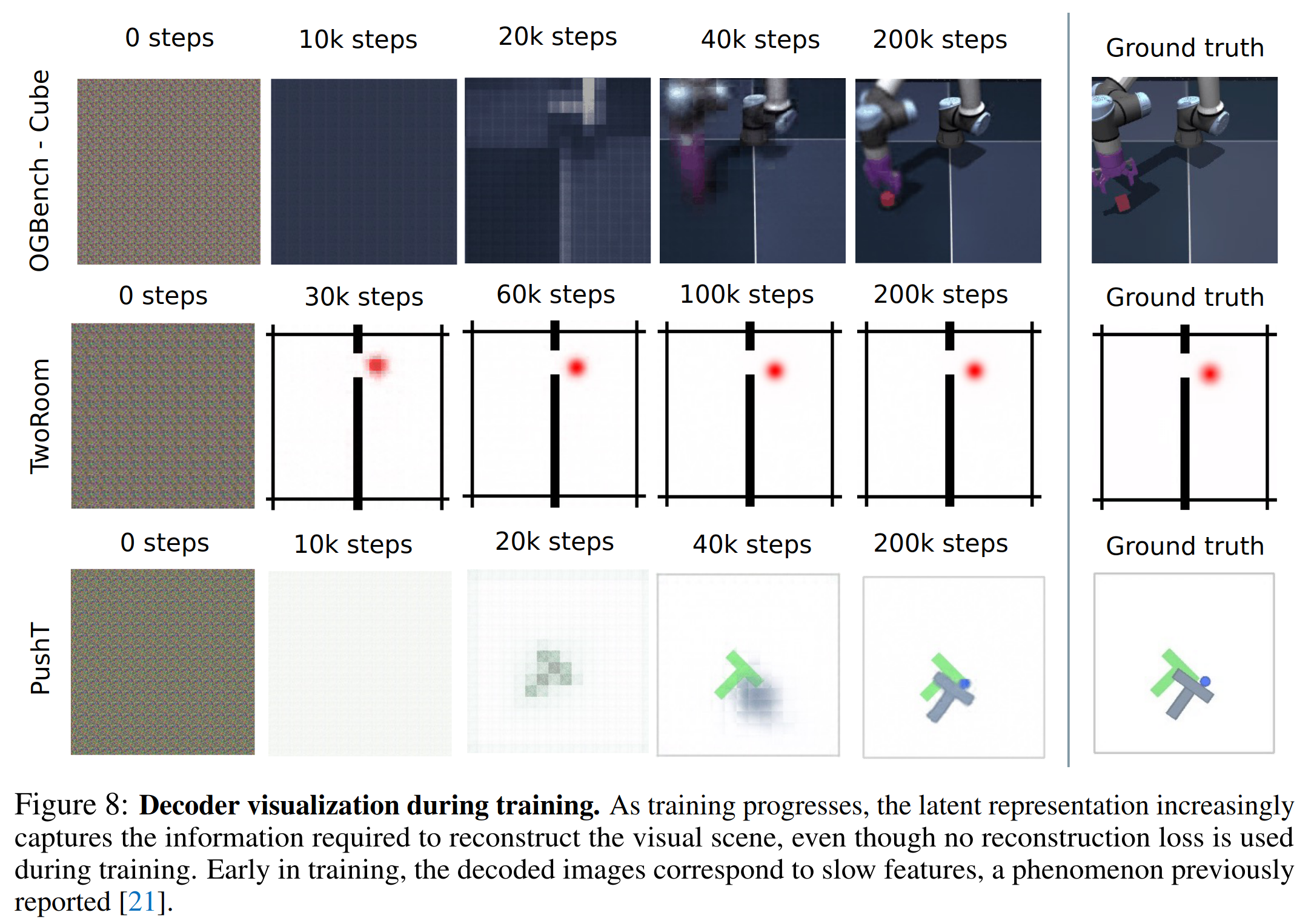
训练了一个可视化decoder,说明latent是具备图像恢复能力的。不过论文没展开将太多实验细节。一般来说应该要OOD地去验证visualization decoder是不是hard code了训练样本。
Visualizing Latent Space
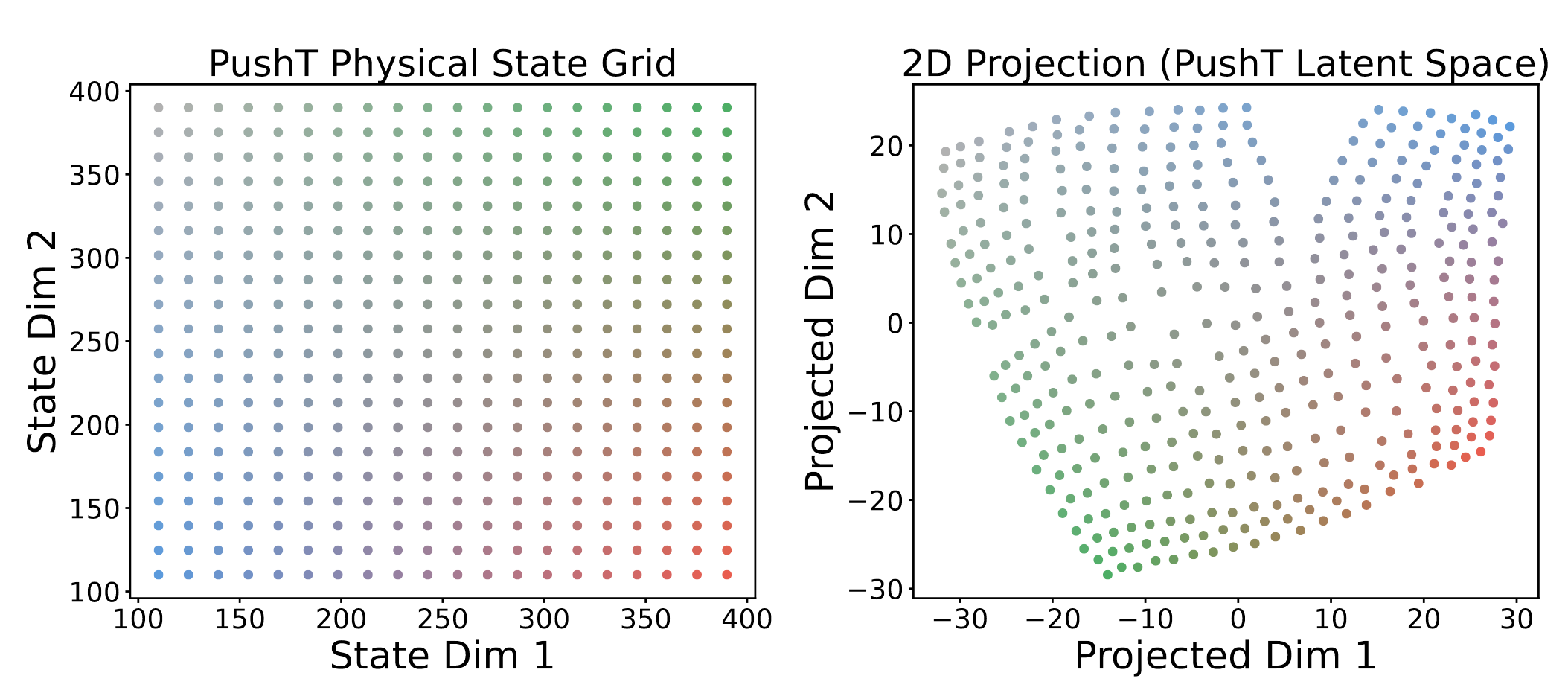
环境表征映射到latent space后,保持了接近的相对结构。但我认为这种低维可视化的说服力有限,只能说没出现高维折叠。
Temporal Latent Path Straightening
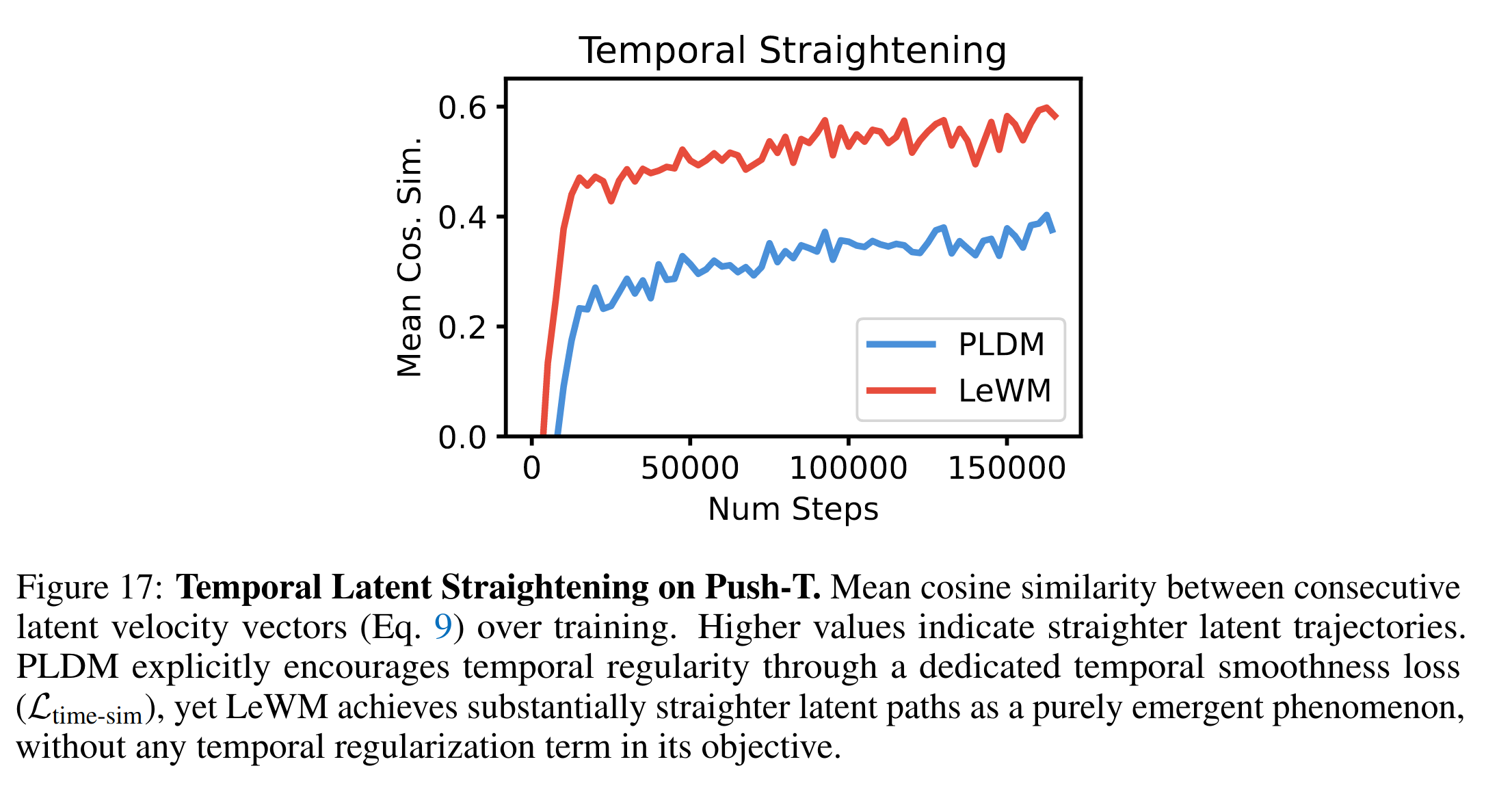
这个我认为是最有意思的,LeWM在没有显式加任何smoothness loss的条件下,涌现出了轨迹平滑的能力。我认为这种能力很可能来自正则化下的紧凑JEPA潜码压缩:历史轨迹越平滑,下一步要处理的问题越简单,越能节约latent表征能力,所以predictor引导模型走出了越来越平滑的轨迹。
图解
借助AI生成了图解,可以辅助理解算法流程: