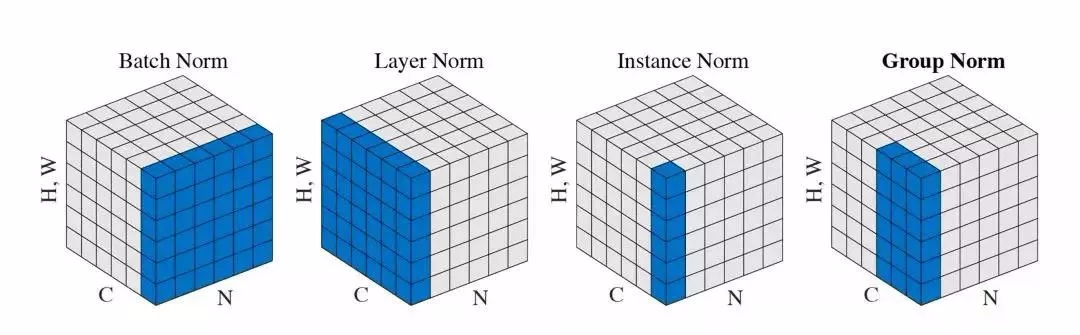
从左到右依次是BN,LN,IN,GN
众所周知,深度网络中的数据维度一般是[N, C, H, W]或者[N, H, W,C]格式,N是batch size,H/W是feature的高/宽,C是feature的channel,压缩H/W至一个维度,其三维的表示如上图,假设单个方格的长度是1,那么其表示的是[6, 6,*, * ]
上图形象的表示了四种norm的工作方式:
BN在batch的维度上norm,归一化维度为[N,H,W],对batch中对应的channel归一化;
LN避开了batch维度,归一化的维度为[C,H,W];
IN 归一化的维度为[H,W];
GN介于LN和IN之间,其首先将channel分为许多组(group),对每一组做归一化,及先将feature的维度由[N, C, H, W]reshape为[N, G,C//G , H, W],归一化的维度为[C//G , H, W]
BN在小样本情况下的影响
1. 统计量估算偏差巨大
BN 的核心依赖于计算当前 Batch 的均值 和方差。
均值/方差不稳定:在小样本下,单个 Batch 的统计特性无法代表整个数据集的分布。由于样本太少,均值和方差会随 Batch 的更替产生剧烈波动。
训练与推理不一致:BN 在训练阶段使用当前 Batch 的统计量,而在测试阶段使用训练过程中累积的移动平均值。当 Batch Size 过小时,训练时使用的“噪声”统计量与测试时的“全局”统计量差异过大,导致模型在推理阶段性能大幅下滑。
2. 梯度震荡与收敛困难
训练不稳定:由于每个 Batch 的统计量波动很大,网络权重的更新方向会变得非常杂乱,导致损失函数难以收敛,甚至出现不收敛的情况。
精度瓶颈:实验表明,随着 Batch Size 的减小(例如从 32 减小到 2),BN 的错误率会呈指数级上升。
3. 特征表达能力受限
BN 会对特征进行归一化处理,这在某种程度上是一种正则化。但在小样本下,这种强制的归一化可能会抹除样本间本就稀缺的区分性特征,导致特征表达变得平庸。
GN——小batch的选择
在 CV 任务中,单样本(Batch Size = 1)时,Group Normalization (GN) 和 Layer Normalization (LN) 都是完全可以使用的。
由于它们都不跨 Batch 计算统计量,因此其归一化效果不受 Batch Size 大小的影响。但在 CV 任务的具体表现上,两者有显著差异:
1. GN vs LN:为什么 CV 任务更倾向于 GN?
虽然两者都能在单样本下工作,但 GN 在计算机视觉中通常比 LN 效果更好。
GN (Group Normalization):将通道(Channel)分组,每组内独立计算均值和方差。这种方式能够捕捉到不同通道间局部的特征关系,更符合图像特征(如边缘、颜色、纹理通常分布在特定的通道组中)的表达规律。
LN (Layer Normalization):是对该层所有通道一起进行归一化。在 CV 中,这等于是把代表不同空间意义的所有特征强行拉齐,容易模糊掉某些重要的判别性特征。
2. 还有另一种选择:IN (Instance Normalization)
在单样本 CV 场景(尤其是风格迁移或图像生成)中,Instance Normalization (IN) 也很常用。
特点:它仅在单个样本的单个通道内计算统计量。
区别:
GN 像是在通道维度上的“分组版” LN。
IN 像是 GN 的极端形式(每组只有一个通道)。
LN 像是 GN 的另一种极端形式(所有通道作为一个大组)。
3. batch size=1, channel=1时,数学上BN/LN就退化为了IN,但是仍有几个很关键的区别
训练与测试的不一致性:BN 在训练时记录的是“移动平均值(Running Mean/Var)”。batch size=1训练时,这些统计量会极其不稳定。到了测试阶段,模型使用这些乱七八糟的平均值去预测,准确率会断崖式下跌。而 IN 在训练和测试时的行为是一致的。
训练崩溃风险:如果特征图被下采样到1x1(例如全局池化前),由于只有一个像素点,方差为 0,BN 的分母会变成 0(或者极小的 epsilon),导致数值不稳定甚至溢出。
3. 归一化方式对比表(针对单样本性能)
核心结论
如果因为显存太小必须用 Batch Size = 1 进行训练,优先尝试 Group Normalization (GN),并将组数(Groups)通常设为 32(这是原论文推荐的经典配置)。
LN一般用在transformer的训练,不过从LLaMA以后,为了更好的数值稳定与更小的计算量,大家多用RMSNorm替代LN了。