
这几天自己写了一个ResNet的框架,按照软件工程的思想组织文件。总结调试遇到的问题:
- 图片格式检查
if data.layers < 3: tmp_img = np.array(data) tmp_img = np.array([tmp_img,tmp_img,tmp_img]) data = Image.fromarray(tmp_img.transpose(1,2,0)) data = self.transforms(data) - loss.backward()要求label必须从0开始连续编号
- 混淆矩阵计算精度用上trace
- 可以针对数据集进行调整,例如针对Tiny-ImageNet这种64×64的小图片,首层Conv可以把7×7调整为5×5等
- 从教程的Alex与ResNet-34出发,自己编写了ResNet-50与ResNet-101网络,基本可以自己创建自己的网络了
- Maxpooling不能随便拿掉,就算在小尺寸图片中
- 测试阶段显存爆炸的一个解决方法:
with torch.no_grad(): output = self.model(lr) - 贴个讲ResNet比较好的页面
ResNet及其变种的结构梳理、有效性分析与代码解读
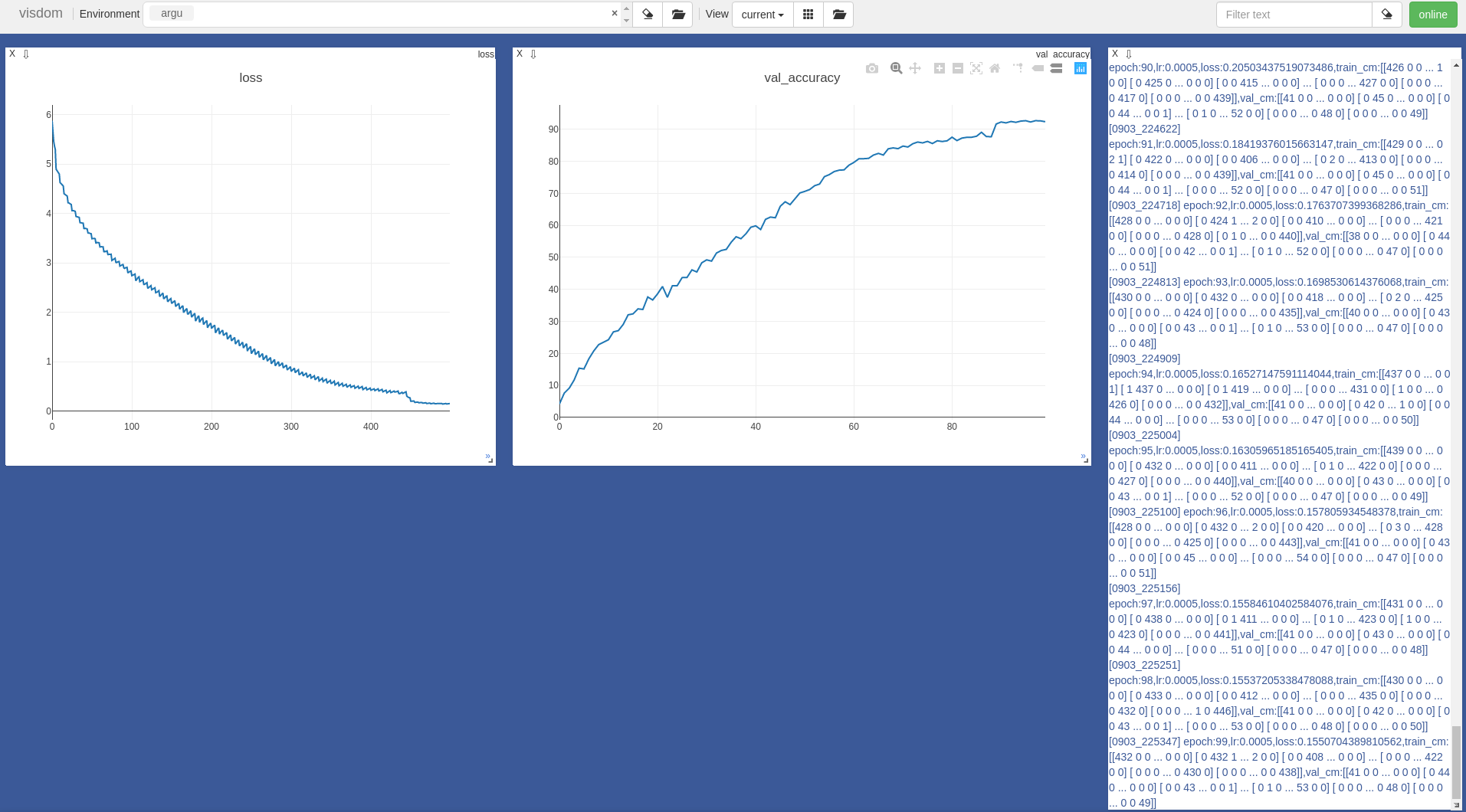
ResNet结构分析 - 2019年09月03日23:23:49,100epochs网络测试准确度从40±5%飙升到了92.66%。做了几点:1、把各stage内stride=2从1×1卷积改到了3×3卷积来做;2、各residual block的add阶段,把relu移动到了shortcut部分(当shortcut不为input时);3、增加了随机旋转、翻转、灰度化、饱和度、对比度、亮度等图像增强技术。灵感来自这篇文章:ResNet on Tiny ImageNet,参考:图像分类:数据增强(Pytorch版),pytorch中transform函数
自己训练过程中的收敛曲线图:(Tiny-ImageNet, ResNet50)
- 高维转置用
Tensor.permute(a,b,c,d,),低维用Tensor.transpose(a,b,),用在tensor(C,H,W)转img(H,W,C)时。 - 适用matplotlib输出时,加上
plt.figure(figsize=(10, 5))可以指定一个比较好的输出图片尺寸(画布大小,非拉伸),具体的函数接口:figure(num=None, figsize=None, dpi=None, facecolor=None, edgecolor=None, frameon=True)- num:图像编号或名称,数字为编号 ,字符串为名称
- figsize:指定figure的宽和高,单位为英寸;
- dpi参数指定绘图对象的分辨率,即每英寸多少个像素,缺省值为80
- facecolor:背景颜色
- edgecolor:边框颜色
- ameon:是否显示边框
plt.figure(figsize=(15, 7.5))
data[:,0, :, :] = data[:,0, :, :] * .228 + .485
data[:,1, :, :] = data[:,1, :, :] * .224 + .465
data[:,2, :, :] = data[:,2, :, :] * .225 + .406
for i in range(0,opt.batch_size):
ax = plt.subplot(8,8,i+1)
plt.tight_layout()
title = words[label[i]].split(',')[0]
ax.set_title(title)
ax.axis('off')
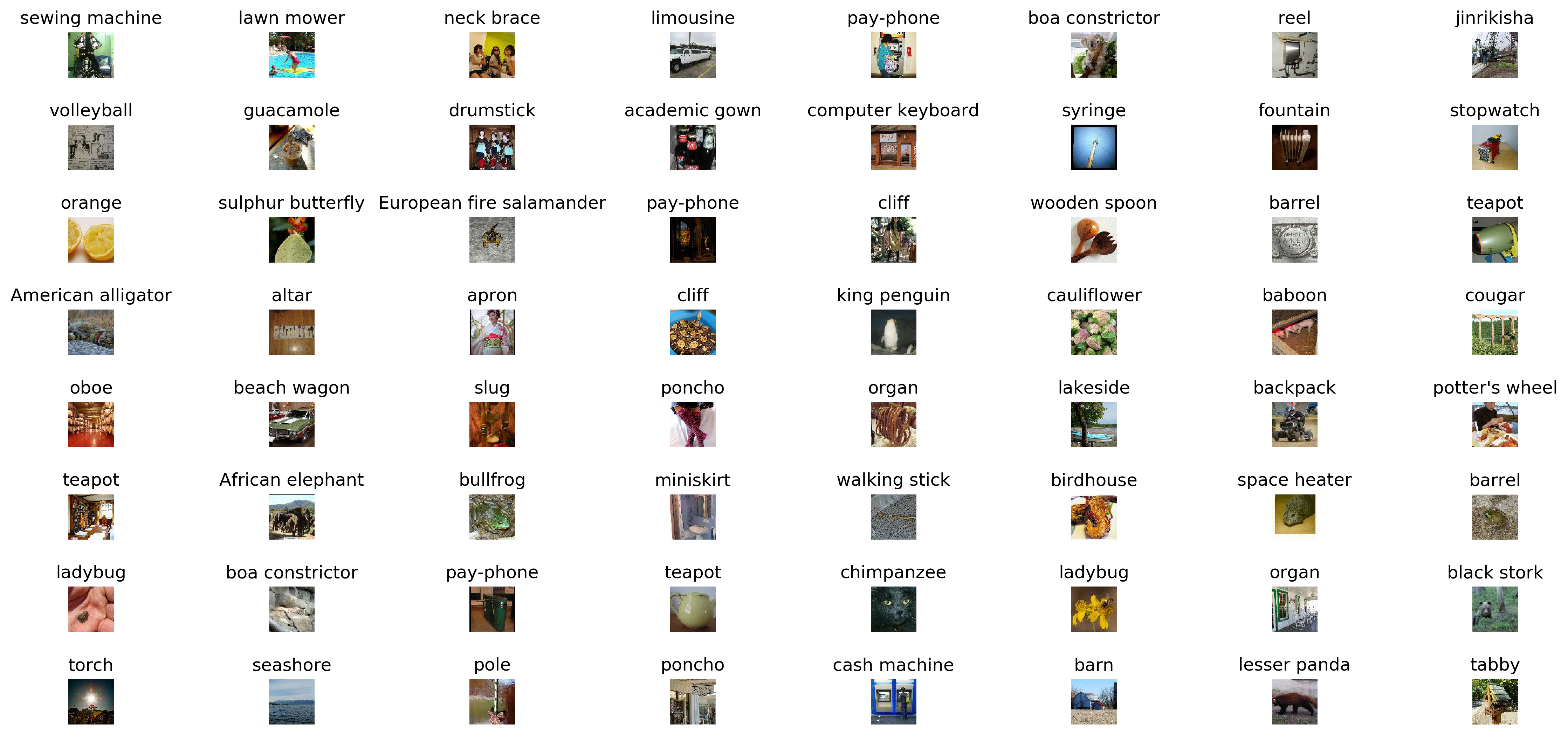
plt.imshow(to_pil(data[i]))可视化部分测试输出结果:
- 由于统一返回值,tensor 返回都为 tensor , 为了获得 python number 现在需要通过.item()来实现,考虑到之前的 loss 累加为 total_loss +=loss.data[0], 由于现在 loss 为0维张量, 0维检索是没有意义的,所以应该使用 total_loss+=loss.item(),通过.item() 从张量中获得 python number.
最后附上带bottleneck的ResNet-50网络结构:

留言