1. 均方误差(Mean Square Error,MSE)
MSE 对大误差非常敏感(平方级惩罚),所以它会逼着模型去尽量拟合那些离群点。
MSE 曲线的特点是光滑连续、可导,便于使用梯度下降算法,是比较常用的一种损失函数。而且,MSE 随着误差的减小,梯度也在减小,这有利于函数的收敛,即使固定学习因子,函数也能较快取得最小值。
平方误差有个特性,就是当 yi 与 f(xi) 的差值大于 1 时,会增大其误差;当 yi 与 f(xi) 的差值小于 1 时,会减小其误差。这是由平方的特性决定的。也就是说, MSE 会对误差较大(>1)的情况给予更大的惩罚,对误差较小(<1)的情况给予更小的惩罚。从训练的角度来看,模型会更加偏向于惩罚较大的点,赋予其更大的权重。
如果样本中存在离群点,MSE 会给离群点赋予更高的权重,但是却是以牺牲其他正常数据点的预测效果为代价,这最终会降低模型的整体性能。
2. 平均绝对误差(Mean Absolute Error,MAE)
MAE 对异常值更鲁棒,但它在 a=0 处不可导,这在优化时偶尔会让人头疼。
值得一提的是,MAE 相比 MSE 有个优点就是 MAE 对离群点不那么敏感,更有包容性。因为 MAE 计算的是误差 y-f(x) 的绝对值,无论是 y-f(x)>1 还是 y-f(x)<1,没有平方项的作用,惩罚力度都是一样的,所占权重一样。针对 MSE 中的例子,我们来使用 MAE 进行求解,看下拟合直线有什么不同。
3. Huber Loss
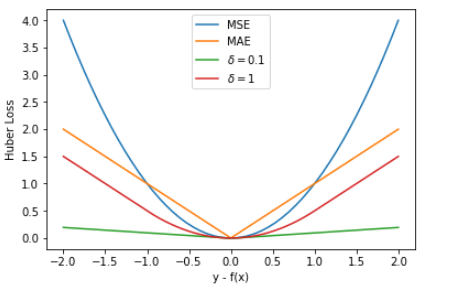
Huber Loss 是前两者的结合体。它在误差较小时使用平方损失,在误差较大时切换为线性损失。
δ 值的大小决定了 Huber Loss 对 MSE 和 MAE 的侧重性,当 |y−f(x)| ≤ δ 时,变为 MSE;当 |y−f(x)| > δ 时,则变成类似于 MAE,因此 Huber Loss 同时具备了 MSE 和 MAE 的优点,减小了对离群点的敏感度问题,实现了处处可导的功能。通常来说,超参数 δ 可以通过交叉验证选取最佳值。
总结
Huber Loss 在 |y−f(x)| > δ 时,梯度一直近似为 δ,能够保证模型以一个较快的速度更新参数。当 |y−f(x)| ≤ δ 时,梯度逐渐减小,能够保证模型更精确地得到全局最优值。因此,Huber Loss 同时具备了前两种损失函数的优点。
表格整理如下:
| 损失函数 | 对异常值敏感度 | 0点处导数 | 优化难度 |
|---|---|---|---|
| MSE | 高(容易被带偏) | 0 | 易(二阶收敛快) |
| MAE | 低(比较佛系) | 未定义 | 中(梯度恒定) |
| Huber | 可调(通过\delta) | 0 | 易(平滑过渡) |