
第一次参加正式的机器学习的数据竞赛,也是第一次完整地使用tensorflow训练一个有实战意义地模型,总结一下。
比赛使用Cleveland库,需要向Cleveland中接入模型的input和logit的tensor节点,而slim封装好的模型中还没有Densenet。目前想要使用Densenet或更新的model就需要自己画graph训练。
这个过程中遇到了几个问题:
1、虽然
Pytorch和Keras(API)非常好用且高效,但他们模型难以转为Tensorflow的ckpt格式并到拿到tensor节点。事实上我是从Pytorch开始正式的训练模型的,仅从事base learning CV研究中可考虑只用Pytorch。但是我认为未来一段时间我应该还是会以Tensorflow + slim框架为主,因为考虑到Tensorflow更为灵活且更流行于工业界。
2、使用tf.slim和tf.data
小数据集可以一次性导入,大数据集下TFRecord时空效率最高(TF原生的张量数据格式、双队列实现、多线程)。
使用tf.data高效读取数据。
3、one-hot
label是什么格式无所谓,都要one-hot成稀疏矩阵。
4、121、161、169
硬件:RTX 2070 + GTX 1066 2, Titan V + P4000
IJCAN对抗样本比赛中,10万图片110类,densenet-121收敛很慢,densenet-169 最快batchsize=32。更换硬件,batchsize=40,收敛明显加快。从 Quora 和 OverStack 上看,很多人采用 Titan X 8,batchsize=128=16*8的方案。
RTX系列的半精度训练不成熟,有机会还是更换硬件成 GTX 1080ti * 2
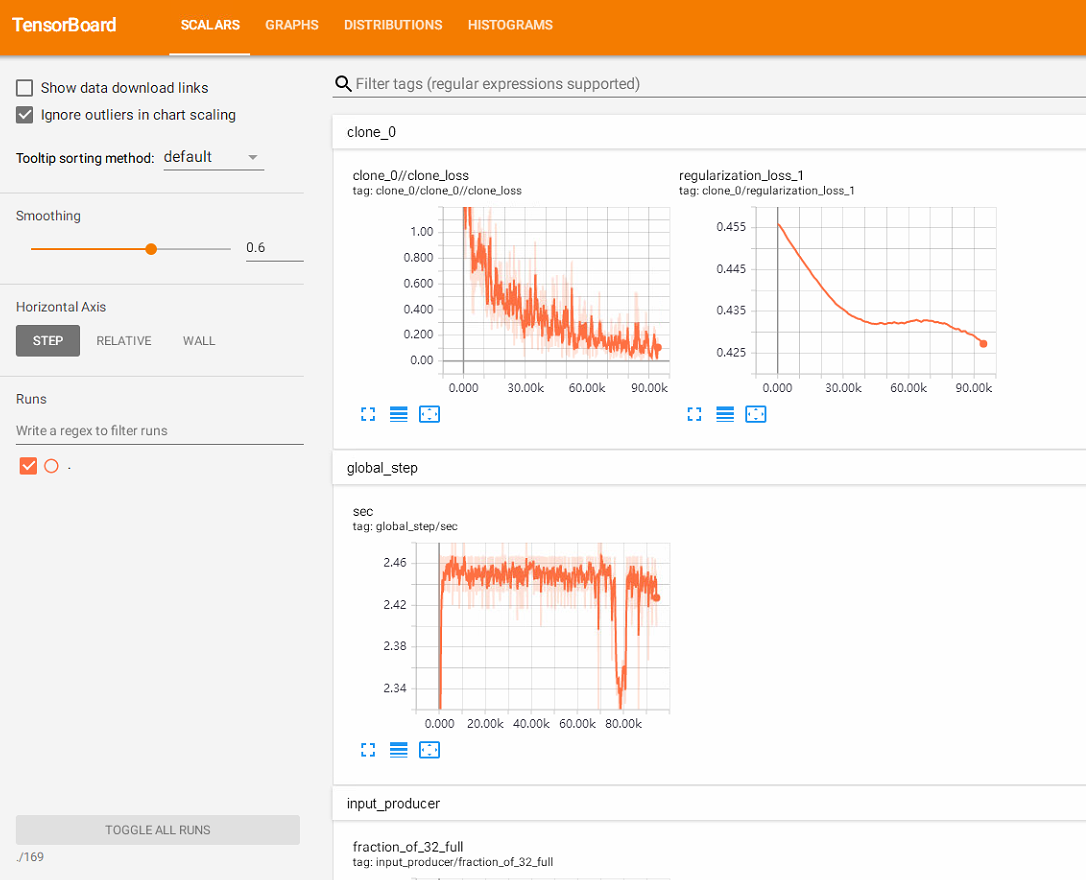
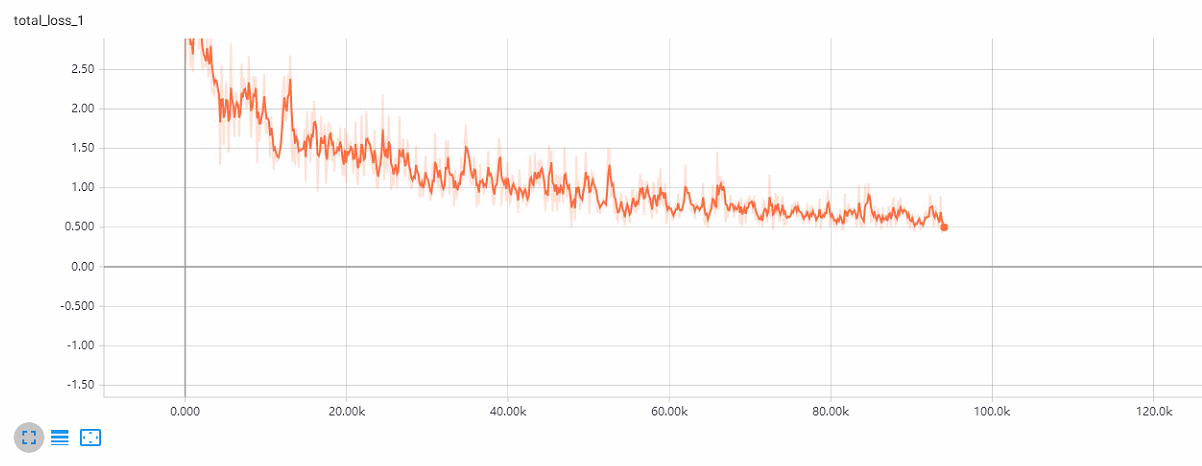
训练效果图
参考
tf.keras 和 keras有什么区别?
TensorFlow数据读取方式(3种方法)
Tensorflow数据读取(代码)
留言